
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Vuejs#JavaScript#프레임워크#개요#개념
- 오라클#튜닝
- EKS란
- abstract
- React #생명주기
- JDK1.8
- SSH #공개키인증
- REST#SOAP#API
- non-locking
- 이펙티스자바
- 모니터링 #k8s #prometheus #metricbeat #elasticsearch #logstash
- React
- Oracle #ANSI #SQL #JOIN
- ssl #개인키 #공개키
- memory #리눅스 #자원관리
- interface
- MQM #웹서버
- java
- JPA #생명주기
- Mysql #RDBMS #설치 #기동 #설정
- React#기초#JS#JavaScrip#개념
- MySQL 5.7 #MySQL 8.0 #차이점 #업그레이드
- 클라우드#클라우드서비스#클라우드개념#IaaS#Paas#Saas
- docker #k8s #배포하기
- k8s
- cors #Authorization
- WEB #HTTP #HTTPS #SSL #통신개념
- MQ#MOM#메시지지향미들웨어#Kafka#ActiveMQ#rabbitMQ
- X.25
- ssh #pem
- Today
- Total
개발노트
INDEX 사용 원리와 장/단점 본문
인덱스, Index
- 색인
- 검색(select)을 빠른 속도로 하기 위해서 사용하는 도구
- 오라클은 테이블 생성 시 인덱스를 따로 생성하지 않아도 자동으로 생성된다. -> PK, Unique 컬럼 자동으로 색인 생성.
-> PK 컬럼 검색속도 >>>>> 일반 컬럼 검색속도 : PK는 자동으로 Index를 생성하기 때문에
검색속도 차이 비교
먼저 일반컬럼을 검색했을때 반환되는 속도는
select * from tblIndex where name ='정소은'; 0.08초
name 컬럼에 인덱스 생성하기
>> create index idxIndexName on tblIndex(name);
색인 후
select * from tblIndex where name ='정소은'; 0.003초
>> 훨씬 빨라진 모습을 보인다.
예를 들어,
고객관리 -> 관리자가 고객이름으로 검색을 많이한다면... -> 인덱스없이 검색하면 느리니까 이름에다가 인덱스를 부여하자 그럼 빨라진다.
인덱스, 장단점 정리
특징
1. 검색 처리 속도를 향상시킨다.
2. 비용이 비싸다 -> 인덱스를 create 해주어야 하기 때문
인덱스 사용해야 하는 경우(중요)
1. 테이블 행의 갯수가 많은 경우.(찾아야할 데이터)
2. 인덱스를 적용한 컬럼이 where 절에서 많이 사용되는 경우 (*****)
3. join할 때 사용하는 컬럼(on 부모테이블.PK = 자식테이블.FK) (*****)
4. 검색 결과가 원본 테이블 데이터 2 ~ 4%에 해당하는 경우 (*****)
5. 해당 컬럼이 null을 포함하는 경우(색인에 null이 제외)
인덱스 사용하면 안 좋은 경우
1. 테이블의 행의 갯수가 적은 경우
2. 검색결과가 원본테이블의 많은 비중을 차지하는 경우.
3. 원본 테이블의 삽입, 수정, 삭제가 빈번한 경우(*****)
select * from tblAddressBook;
비고유 인덱스
--job은 중복값이 존재하던 컬럼임
--인덱스가 걸린 컬럼 > job > 중복값 존재
>> create index idxIndexJob on tblIndex(job);
고유 인덱스
--인덱스가 걸린 컬럼 > seq > PK, Unique
>> create index idxIndexSeq on tblIndex(seq); -- PK라 색인도 중복되지 않는다.
단일 인덱스
--인덱스 걸 컬럼이 1개일때..
>> create index idxIndexEmail on tblIndex(email) email 컬럼에만 index 부여
select * from tblIndex where email = 'back@live.com'; --> idxIndexEmail동작 -> 빠른속도로 검색
select * from tblIndex where email = 'back@live.com' and age = 44; --> idxIndexEmail 동작 X --> 왜냐면 age와 같이 where 절의 조건으로 사용되었기 때문.
결합(다중) 인덱스
>> create index idxIndexEmailAge on tblIndex(email,age); --> 이렇게 해주어야 위의 상황에서 인덱스 효과를 받을 수 있다.
select * from tblIndex where name = '김길동'; --idxIndexName 동작 O
select * from tblIndex where substr(name,1,1) = '김'; --idxIndexName 동작 X --> 함수로 감싸여졌기 때문에.. --> 즉 순수컬럼값으로만 검색해야한다.
--> create index idxIndexLastName on tblIndex(substr(name,1,1));
select * from tblIndex where (height + weight)>200;
create index idxIndexBMI
on tblIndex((height + weight));
--하나의 테이블에 여러개의 인덱스가 필요할 수 있다.
INDEX를 사용하는 가장 큰 이유는 속도의 향상을 위해서 사용됩니다. INDEX 구조를 만들어주면 FULL SCAN에서 모든 테이블 데이터를 읽어오는 방법과는 다르게 ROOT - BRANCH - LEAF - DATA BLOCK총 4번의 IO를 통해서 접근이 가능합니다. 데이터가 100건이든 100만건이든 속도차이는 많이 안난다는 장점이 있습니다.
INDEX란?
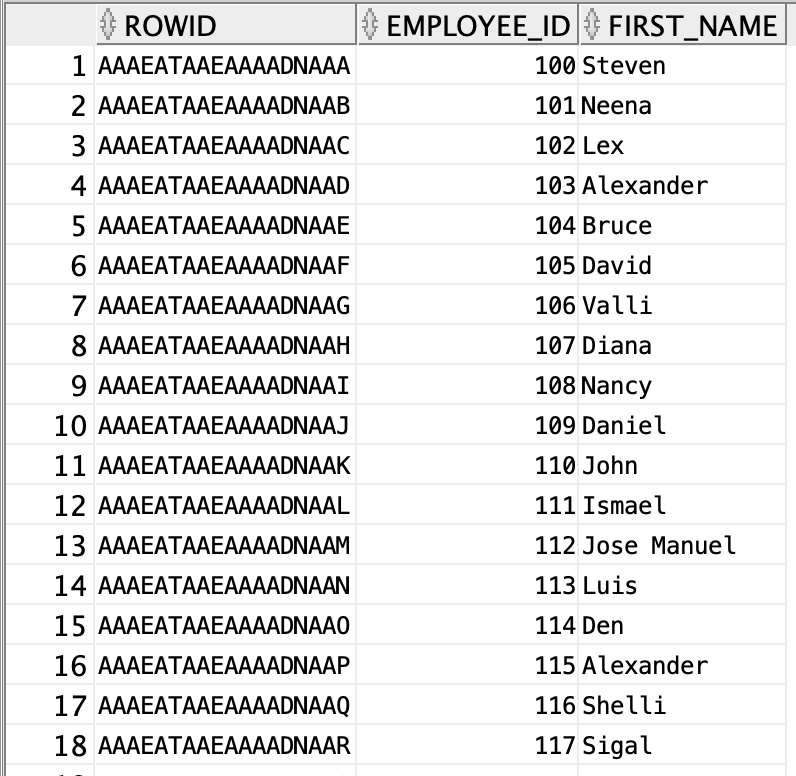
모든 테이블에는 ROWID라는 칼럼이 있습니다. ROWID = FILE 번호 + BLOCK 번호 + ROW번호로 구성되어 있습니다. "7번파일에 132번 블록에 3번째" 이런 식으로 해당 데이터의 주소라고 볼 수 있습니다. INDEX는 이런 ROWID를 통해 DATA BLOCK에 접근 합니다. INDEX는 데이터를 빠르게 찾기 위해 오름차순으로 정렬된 주소체계라고 표현하고 싶습니다.
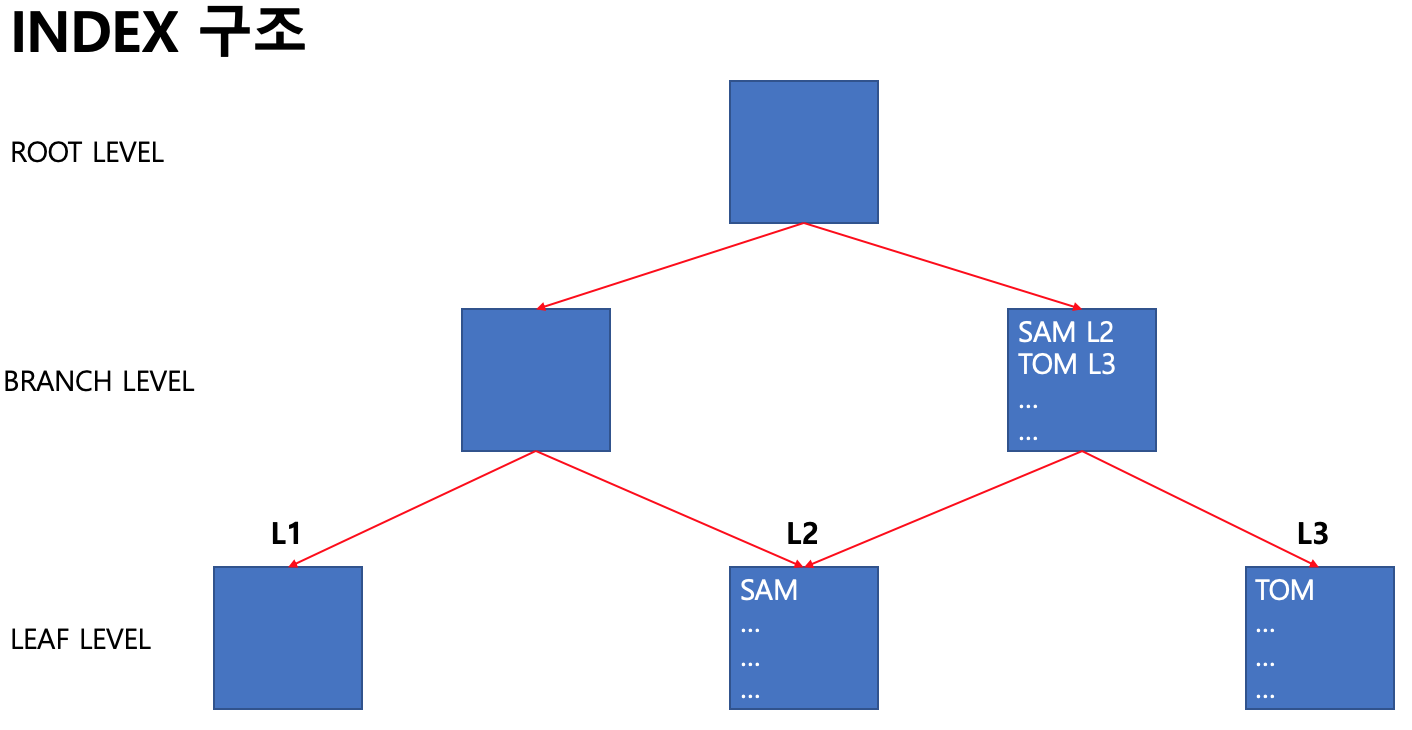
INDEX는 ROOT, BRANCH, LEAF로 구성되어 있는 계층적 구조를 갖고 있습니다. 오라클 서버에서 FULL SCAN보다 INDEX SCAN이 유리하다고 판단 되었을 때 생성된 INDEX의 ROOT 부터 찾습니다. ROOT에는 BRANCH 블럭의 시작점에 대한 정보를 갖고 있어 찾고자 하는 데이터의 위치가 어느 BRANCH에 위치하는지 알 수 있습니다. BRANCH LEVEL에서도 마찬가지로 LEAF 블럭에 대한 시작점 정보를 갖고 있어 어느 LEAF에 포함되어 있는지 알수 있습니다. 마지막으로 LEAF에서 해당 데이터의 ROWID를 알 수 있습니다. 찾았을때 BLOCK의 ROWID를 알아냈으니, 바로 해당 데이터로 찾아갈 수 있어 빠른 검색이 가능합니다.
INDEX를 사용하면 무조건 빠른가?
꼭 그런것 만은 아닙니다. 상황과 어떤 컬럼에 INDEX를 사용하는지에 따라 어쩔때는 FULL SCAN이 유리할 수 있습니다. 직관적인 예시를 들자면 1개의 데이터가 있는 테이블과 100만개의 데이터가 들어 있는 테이블입니다. 100만개의 데이터가 들어있는 테이블이라면 FULL SCAN보다는 INDEX SCAN이 유리하겠지만, 1개의 데이터가 들어있는 테이블은 굳이 INDEX SCAN 없이 FULL SCAN이 빠를 것 입니다.
그외에 읽는 블록의 갯수뿐만 아니라, IO하는 횟수도 중요합니다. INDEX SCAN 한 블럭씩 읽어야 합니다. 즉, IO의 단위가 1블럭이 됩니다. FULL SCAN의 경우 모두 다 읽어야하지만 DB_FILE_MULTIBLOCK_READ_COUNT 파라미터의 설정에 따라 한번에 여러 블럭을 읽어 INDEX SCAN보다 효율적일 수 있습니다.
오라클 서버에서는 FULL SCAN을 할지 INDEX SCAN을 할지 여러 변수로 비교하여 성능이 더 좋다고 판단되는 방법으로 SCAN 작업을 합니다. 그럼 어차피 오라클 서버가 판단해주니까 모든 컬럼에 INDEX를 만들어주는게 유리한거 아닌가요?

모든 컬럼에 INDEX를 추가해줘서 빠른 검색이 가능하면 좋겠지만... INDEX를 만들어주는데는 저장공간이 필요합니다. 그러므로 속도 향상에 비해 단점들의 COST를 비교해서 사용할지 말지를 정해야합니다.
INDEX는 SELECT 구문에서는 확실히 좋고 빠릅니다. 하지만 INSERT, UPDATE, DELETE 작업을 할때는 INDEX에 대한 수정도 필요합니다. INDEX가 없더라면 그냥 작업을 하면 되지만, INDEX가 있는 경우, 오름차순되어 있는 INDEX에 새로 변경된 데이터를 맞춰 다시 수정을 합니다.
INDEX는 이런 저하되는 성능 보다 SELECT로 데이터를 검색했을 때 검색 속도를 향상시켜주는 퍼포먼스가 더 높게 평가되어 사용합니다.
INDEX는 언제 사용 할까요?

1. 구별되는 값이 많은 칼럼
PRIMARY KEY로 지정되는 칼럼에는 UNIQUE한 INDEX가 생성됩니다. 검색하려는 모든 데이터가 고유한 값이라면, INDEX 구조 내에서도 중복되는 데이터 확인 필요없이 가장 최적화 되어 있는 상태입니다.
2. WHERE절에서 자주 조회되는 칼럼
WHERE절에서 사용이 안된다면 굳이 INDEX를 만들어줄 필요가 없다. STORAGE만 차지하고 사용도 안한다면 없애주는게 도움입니다. 중복되는 데이터가 있다고 하더라도 자주 WHERE절의 조건으로 사용되는 칼럼이라면 INDEX SCAN이 효율적일 것입니다.
3. 큰 테이블에서 적은 데이터가 필요할 때

3번째는 회사의 재직상태를두고 예시를 들어보겠습니다. 테이블에는 재직 상태에 대한 칼럼이 있습니다. 그런데 재직이 90% 이상을 차지하고, 나머지 상태가 얼마 안되는 비중을 차지했을때 INDEX에는 NULL값이 들어갈 수 없다는 특징을 사용할 수 있습니다. INDEX에는 NULL값이 들어갈 수 없습니다. 재직상태에 INDEX 칼럼을 사용하기 위해 가장 비율을 많이 차지하고 있는 "재직"을 NULL로 INSERT하고 나머지 상태는 따로 구분합니다.
이렇게 데이터를 입력해주면, FULL SCAN으로 검색 했더라면 100건을 모두 탐색 했어야하는데 INDEX를 활용해서 5건의 데이터에 대한 INDEX SCAN을 진행하게 됩니다.
INDEX 유지보수
지금까지의 내용으로 봤을 때, INDEX는 단점 보다는 장점이 많은 것 같고, 데이터베이스를 사용한다면 무조건 사용할 수 밖에 없는 것 같습니다. 좋은 도구인 만큼, 유지보수도 필요합니다.
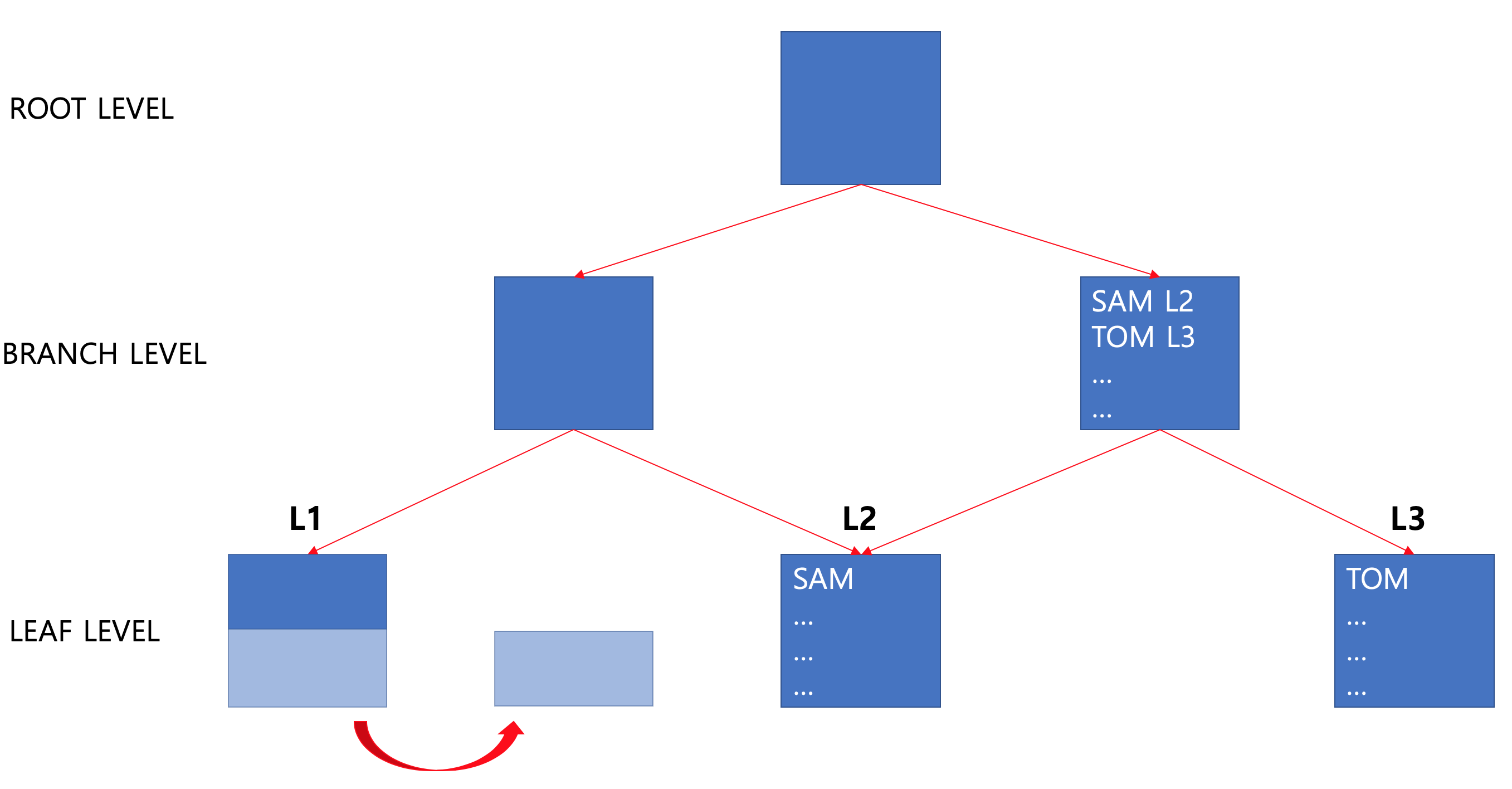
상품구매, 주식거래, 근퇴확인 등 INSERT 작업이 지속적으로 이루어지는 테이블은 INDEX의 크기도 계속 커지게 되어 있습니다. 또 INDEX의 특성상 데이터가 INSERT 될때 테이블과 달리 자리가 정해져 있습니다. 만약 들어갈 BLOCK에 이미 다른 데이터가 들어가 있고 꽉차 있는경우, 데이터를 잘라서 새로운 LEAF 블록에 절반을 넣습니다. 여기서 한건이 아닌 절반의 데이터를 분할 하는 이유는 앞으로 더 들어올 데이터의 자리를 미리 마련해주기 위해서 입니다.
이런 작업이 계속 진행되다보면 LEAF BLOCK의 수는 수도 없이 많아지고 계속 분할하게 되면 메모리에 올렸는데 아무 데이터도 없는 LEAF BLOCK이 생겨날 수도 있습니다. 그만큼 메모리에 좋지 않습니다. 이런 문제를 해결하기 위해 DBA가 인덱스를 재구성해주는 튜닝작업을 합니다.
'DB > Oracle' 카테고리의 다른 글
| [ORACLE] Full Table Scan (0) | 2022.11.01 |
|---|---|
| TO_DATE - Convert String to Datetime (0) | 2022.10.24 |
| Oracle에서 Join문 사용 및 간단하게 사용법 & 개념 익히기 (0) | 2022.08.04 |


